Bilim kurgu dünyasından gerçeğe dönüşen yapay zeka (AI) terimini, 1950’li yılların ortalarında bilgisayar bilimcisi John McCarthy ilk kez ortaya attı. “Yapay zeka” terimi, başlangıçta yalnızca bir araştırma alanıydı. O dönemdeki bilgisayarlar, karmaşık matematiksel hesaplamaları hızlı bir şekilde yapıyordu. Ancak insan benzeri düşünme yeteneklerinden yoksun olan basit makinelerdi. Bununla birlikte, Alan Turing gibi öncü bilim insanlarının makinelerin düşünme yeteneğine sahip olup olamayacağına dair soruları bu alana ilgiyi artırdı. Turing’in 1950 yılında ünlü makalesi “Computing Machinery and Intelligence”ı yayımladı. Makalede, makinelerin insan gibi düşünme yeteneğine sahip olup olmadığını test etmek için bir kriter önerdi: Turing Testi. Bu ilk teorik adımlar, zamanla pratik uygulamalara dönüştü. Daha sonra bugün bildiğimiz modern yapay zeka teknolojilerinin temelini oluşturdu.
İlk yıllarda AI uygulamalarının yetenekleri sınırlıydı. Daha sonra bilgisayarların hesaplama gücündeki artış ve büyük veri kümelerinin daha fazla kullanılmasıyla hızla gelişti. Özellikle ChatGPT, DALL·E, Midjourney gibi uygulamalarla hayatımıza yeni bir kavram girdi: Üretken yapay zeka! Bu yeni teknoloji; bilgisayar sistemlerinin metin, görüntü, ses gibi farklı veri türlerini işler. Sonucunda da orijinal içerik oluşur.
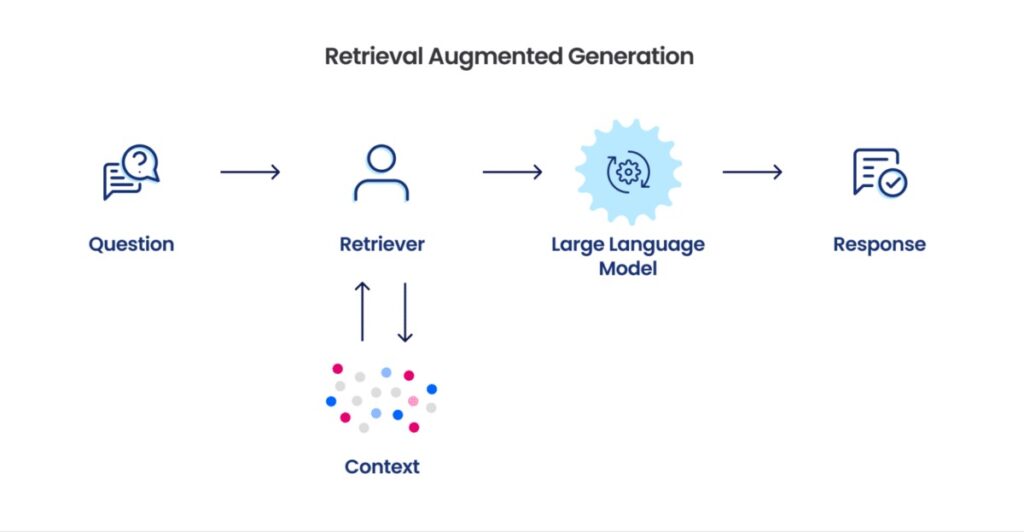
Buna paralel olarak, RAG (Retrieval-Augmented Generation) modeli de son dönemlerde şirketlerin kullandığı bir AI tekniği olarak karşımıza çıkıyor. RAG; büyük dil modellerini (LLM) dış bilgiyle geliştiren, üretken bir yapay zeka tasarım tekniğidir. Makine öğrenimi ve doğal dil işleme modellerinin birleşimi olan bu yöntem, büyük veri tabanlarından bilgiyi çekiyor. Daha sonra bu bilgiyi kullanarak daha doğru ve bilgiye dayalı metin üretimi sağlıyor.

RAG uygulaması nasıl çalışır?
- Retrieve (Alma): Model ilk adımda, büyük veri tabanlarından veya geniş bir veri havuzundan ilgili bilgiler çeker. Bu adım, genellikle özel olarak tasarlanmış bir bilgi çekme sistemini veya bir arama motorunu kullanarak gerçekleşir. Örneğin, bir konu veya sorunun belirli yönleriyle ilgili makaleler, dokümanlar veya web sayfaları çekilir.
- Augment (Artırma): Çekilen bu bilgiler, bir doğal dil işleme modeline veya metin üretme modeline beslenir. Model, bu bilgileri anlamak ve mevcut bağlam içinde doğru şekilde kullanmak için eğitilmiştir. Bu aşamada, doğrulanmış bilgiler metin üretimi için bir zemin sağlar ve kaliteyi artırır.
- Generate (Üretme): Son adım, modelin bu bilgileri kullanarak yeni metinler oluşturmasıdır. Burada amaç; çekilen bilgileri doğru bir şekilde yansıtmak ve yeni, orijinal içerikler üretmektir. Bu süreçte, kullanılan model genellikle büyük ölçüde dil üretimine odaklanan ve önceki adımlarda çekilen bilgileri anlamak için eğitilmiş bir yapay zeka modelidir.
Diğer dil modellerinden farkı nedir?
Geleneksel dil modellerinde, yanıtlar yalnızca eğitim aşamasında öğrenilmiş kalıplar ve bilgiler kullanılarak oluşur. Bununla birlikte bu modeller, eğitildikleri verilerle sınırlıdır. Bu da genellikle derin veya eksik bilgili yanıtlar verir. RAG ise harici verileri çekerek bu sınırlamayı ortadan kaldırıyor. RAG sistemi, bir sorgu yapıldığında büyük bir veri kümesinden veya bilgi tabanından ilgili verileri alır. Ardından bu verileri bilgilendirmek ve yönlendirmek için kullanır.
RAG, özellikle karmaşık metinlerin oluşturulması gereken durumlarda kullanışlıdır. Örneğin, derinlemesine araştırma gerektiren makaleler, teknik raporlar veya öğretici içerikler gibi alanlarda etkilidir. Bu teknik, bilginin doğruluğunu ve içeriğin derinliğini artırır. Ayrıca insan yazarların yaratıcılığına ve bilgiye dayalı metin üretimine önemli katkılar da sağlar.